Implement a CDC-based data replication for PostgreSQL using Debezium
CDC Introduction
In databases, change data capture (CDC) is a set of software design patterns used to determine and track the data that has changed (the “deltas”) so that action can be taken using the changed data. The result is a delta-driven dataset [1].
Debezium Introduction
Debezium is an open source project that provides a low latency data streaming platform for change data capture (CDC) [2]. It records all row-level changes within each database table in a change event stream, and applications simply read these streams to see the change events in the same order in which they occurred [3].
More details please find in debezium.io.
Debezium Architecture [4]
Most commonly, you deploy Debezium by means of Apache Kafka Connect. Kafka Connect is a framework and runtime for implementing and operating:
- Source connectors such as Debezium that send records into Kafka
- Sink connectors that propagate records from Kafka topics to other systems
The following image shows the architecture of a change data capture pipeline based on Debezium:
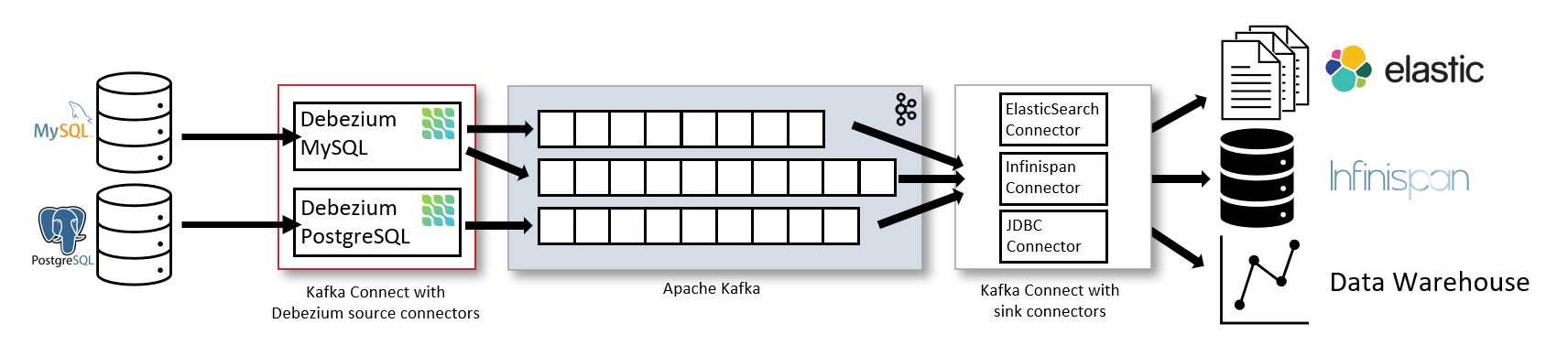
As shown in the image, the Debezium connectors for MySQL and PostgreSQL are deployed to capture changes to these two types of databases. Each Debezium connector establishes a connection to its source database:
- The MySQL connector uses a client library for accessing the
binlog. - The PostgreSQL connector reads from a logical replication stream.
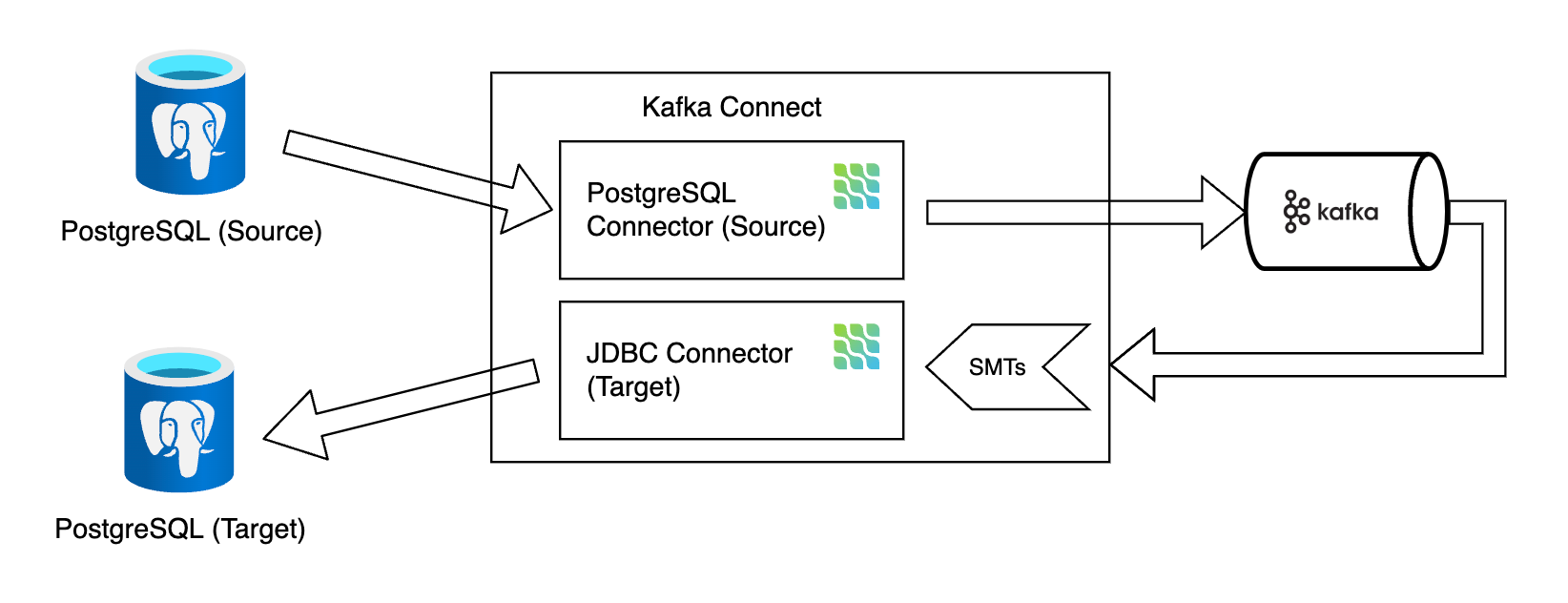
The following diagram illustrates the architecture for PostgreSQL replication with Debezium:
Debezium Features [5]
Debezium provides a set of source connectors for Apache Kafka Connect. Each connector ingests changes from a different database by using that database’s features for change data capture (CDC). Unlike other approaches, such as polling or dual writes, log-based CDC as implemented by Debezium:
- Ensures that all data changes are captured.
- Produces change events with a very low delay while avoiding increased CPU usage required for frequent polling. For example, for MySQL or PostgreSQL, the delay is in the millisecond range.
- Requires no changes to your data model, such as a “Last Updated” column.
- Can capture deletes.
- Can capture old record state and additional metadata such as transaction ID and causing query, depending on the database’s capabilities and configuration.
Five Advantages of Log-Based Change Data Capture is a blog post that provides more details.
Debezium connectors capture data changes with a range of related capabilities and options:
- Snapshots: optionally, an initial snapshot of a database’s current state can be taken if a connector is started and not all logs still exist. Typically, this is the case when the database has been running for some time and has discarded transaction logs that are no longer needed for transaction recovery or replication. There are different modes for performing snapshots, including support for incremental snapshots, which can be triggered at connector runtime. For more details, see the documentation for the connector that you are using.
- Filters: you can configure the set of captured schemas, tables and columns with include/exclude list filters.
- Masking: the values from specific columns can be masked, for example, when they contain sensitive data.
- Monitoring: most connectors can be monitored by using JMX.
- Ready-to-use message transformations for message routing, filtering, event flattening, and more; see Transformations for an overview of all the SMTs coming with Debezium.
See the connector documentation for a list of all supported databases and detailed information about the features and configuration options of each connector.
Debezium can also be used as library embedded into your JVM-based applications; via Debezium Server, you can emit change events to messaging infrastructure like Amazon Kinesis, Google Cloud Pub/Sub, Apache Pulsar, etc.
Debezium PostgreSQL Connector (Source Connector) [6]
Introduction
The Debezium PostgreSQL connector captures row-level changes in the schemas of a PostgreSQL database.
The first time it connects to a PostgreSQL server or cluster, the connector takes a consistent snapshot of all schemas. After that snapshot is complete, the connector continuously captures row-level changes that insert, update, and delete database content and that were committed to a PostgreSQL database. The connector generates data change event records and streams them to Kafka topics. Applications and services consume data change event records from that topic.
How it works
PostgreSQL’s logical decoding feature was introduced in version 9.4. It is a mechanism that allows the extraction of the changes that were committed to the transaction log and the processing of these changes in a user-friendly manner with the help of an output plug-in. The output plug-in enables clients to consume the changes.
The PostgreSQL connector contains two main parts that work together to read and process database changes:
- A logical decoding output plug-in. As of PostgreSQL 10+, there is a logical replication stream mode, called
pgoutputthat is natively supported by PostgreSQL. This means that a Debezium PostgreSQL connector can consume that replication stream without the need for additional plug-ins. This is particularly valuable for environments where installation of plug-ins is not supported or not allowed. For more information, see Setting up PostgreSQL. - Kafka Connect connector that reads the changes produced by the chosen logical decoding output plug-in. It uses PostgreSQL’s streaming replication protocol, by means of the PostgreSQL JDBC driver.
Deployment
Please find details in:
- Debezium connector for PostgreSQL :: Debezium Documentation
- debezium-examples/tutorial at main · debezium/debezium-examples (github.com)
- container-images/connect/2.7 at main · debezium/container-images (github.com)
Initial load with Snapshots [7]
Most PostgreSQL servers are configured to not retain the complete history of the database in the WAL segments. This means that the PostgreSQL connector would be unable to see the entire history of the database by reading only the WAL. Consequently, the first time that the connector starts, it performs an initial consistent snapshot of the database.
The default behavior for performing a snapshot consists of the following steps. You can change this behavior by setting the snapshot.mode connector configuration property to a value other than initial.
- Start a transaction with a SERIALIZABLE, READ ONLY, DEFERRABLE isolation level to ensure that subsequent reads in this transaction are against a single consistent version of the data. Any changes to the data due to subsequent
INSERT,UPDATE, andDELETEoperations by other clients are not visible to this transaction. - Read the current position in the server’s transaction log.
- Scan the database tables and schemas, generate a
READevent for each row and write that event to the appropriate table-specific Kafka topic. - Commit the transaction.
- Record
Recapturing data with Ad hoc snapshots [8]
In some situations the data that the connector obtained during the initial snapshot might become stale, lost, or incomplete. To provide a mechanism for recapturing table data, Debezium includes an option to perform ad hoc snapshots.
- To provide flexibility in managing snapshots, Debezium includes a supplementary snapshot mechanism, known as incremental snapshotting. In an incremental snapshot, instead of capturing the full state of a database all at once, as in an initial snapshot, Debezium captures each table in phases, in a series of configurable chunks.
- To provide more flexibility in managing snapshots, Debezium includes a supplementary ad hoc snapshot mechanism, known as a blocking snapshot. A blocking snapshot behaves just like an initial snapshot, except that you can trigger it at run time.
Data change events [9]
The Debezium PostgreSQL connector generates a data change event for each row-level INSERT, UPDATE, and DELETE operation. Each event contains a key and a value. The structure of the key and the value depends on the table that was changed. Details please see in Data change events - Debezium connector for PostgreSQL.
Debezium JDBC Connector (Sink Connector) [10]
The Debezium JDBC connector is a Kafka Connect sink connector implementation that can consume events from multiple source topics, and then write those events to a relational database by using a JDBC driver. This connector supports a wide variety of database dialects, including Db2, MySQL, Oracle, PostgreSQL, and SQL Server.
Transformations
Message Filtering [11]
By default, Debezium delivers every data change event that it receives to the Kafka broker. However, in many cases, you might be interested in only a subset of the events emitted by the producer. To enable you to process only the records that are relevant to you, Debezium provides the filter single message transform (SMT).
Details see in Message Filtering :: Debezium Documentation.
Topic Routing [12]
By default, changes from one database table are written to a Kafka topic whose name corresponds to the table name. If needed, you can adjust the destination topic name by configuring Debezium’s topic routing transformation. For example, you can:
- Route records to a topic whose name is different from the table’s name
- Stream change event records for multiple tables into a single topic
Details see in Topic Routing :: Debezium Documentation.
Custom Transformors
You can build your own custom transformation by implementing a Kafka Connect and then enable it in Debezium.
See more details in:
- Create Custom Kafka Connect Single Message Transforms for Confluent Platform - Confluent Documentation
- confluentinc/kafka-connect-insert-uuid: A Kafka Connect SMT to add a UUID to a record (github.com)
- kafka/connect/transforms/src/main/java/org/apache/kafka/connect/transforms/Filter.java at trunk · apache/kafka (github.com)
SMT predicates [13]
When you configure a single message transformation (SMT) for a connector, you can define a predicate for the transformation. The predicate specifies how to apply the transformation conditionally to a subset of the messages that the connector processes. You can assign predicates to transformations that you configure for source connectors, such as Debezium, or to sink connectors.
Limitations
- Cannot produce change events for tables that have different structures on the same topic. Therefore, the replication for different tables runs parallel.
- Tables cannot be replicated in a transaction as their original business transaction.
- An initial load will fail if there are foreign keys on tables. This is because the replication of different tables is out of order.
- Replication filtering based on a foreign key relationship is not supported.
- An official connector for HANA is not supported
- The schema evolution supported by the connector is quite basic. It simply compares the fields in the event structure to the table’s column list, and then adds any fields that are not yet defined as columns in the table. If a column’s type or default value changes, the connector does not adjust them in the destination database. If a column is renamed, the old column is left as-is, and the connector appends a column with the new name to the table; however existing rows with data in the old column remain unchanged. These types of schema changes should be handled manually.
[DBZ-8211] Debezium connect docker image - SMT not fully supported - Red Hat Issue Tracker
Alternatives
AWS Database Migration Service
References
- Change data capture - Wikipedia
- debezium/debezium: Change data capture for a variety of databases. Please log issues at https://issues.redhat.com/browse/DBZ. (github.com)
- What is it? :: Debezium Documentation
- Debezium Architecture :: Debezium Documentation
- Debezium Features :: Debezium Documentation
- Debezium connector for PostgreSQL :: Debezium Documentation
- Snapshots - Debezium connector for PostgreSQL
- Ad hoc snapshots - Debezium connector for PostgreSQL
- Data change events - Debezium connector for PostgreSQL
- Debezium connector for JDBC :: Debezium Documentation
- Message Filtering :: Debezium Documentation
- Topic Routing :: Debezium Documentation
- Applying transformations selectively :: Debezium Documentation